Twitter-Archive-Parser Analysis
During the past few weeks, I have been developing a Python script that aims to uncover Twitter data through the data archive that a user can download. This is slightly different from a cloud extraction, such as with Magnet axioms Cloud Pull feature, because doing an archive download sends the user a zip file with many JavaScript files containing their information. This archive has more information about a user than the Axiom pull, but is harder to manually search through. This is why I created a script to parse out some of the many files in the archive.
Upon running the script, which took less than 4 minutes, data is parsed and outputted to the user specified output SQLite3 database. Run time of the script is impacted by the number of account IDs needed to be requested and the general content size of the account. This is due to the fact no account usernames or handles are recorded in this archive, only numeric account IDs. this can be overcome by one of two ways: implement the Twitter API, or make HTTP requests to Twitter. For this script, I used HTTP requests. To lessen the amount of HTTPs requests needed to be made, a dictionary is made with the account ID as the key, and username + handle as the values. Each time an account ID is parsed, the script checks the dictionary to see if it is a known account ID with an already parsed out username + handle, if so, no HTTPS request is made, and if not, an HTTPS request is made, then data appended to the dictionary. This method lessened run time by over 500% on my personal Twitter archive. If you’re interested, download it here.
The outputted database has the following fields, and the data inside each field:
Account Info
Contains data obtained from the account.js file. Which is parsed from & into the following:


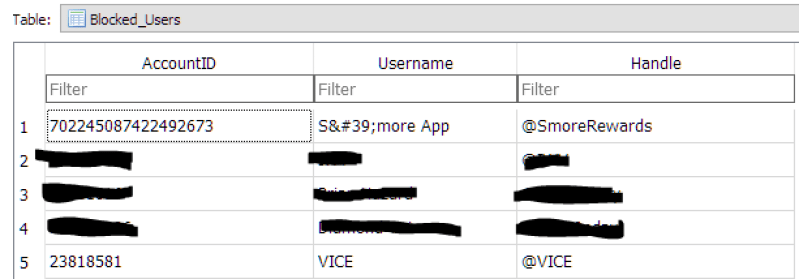
Blocked Users
Contains data obtained from the block.js file. This data is useful for an investigation such as a harassment case, as you can see that the user in question is actively blocking a potential suspect. The file is parsed from & into the following:

Connected Applications
Contains data from connected-application.js which shows what apps were given permission to use the user accounts data. This has less functionality than Axioms, where its able to tell an investigator which Tweet was sent by what device.

![]()

Direct Messages
Contains data from direct-message.js which contains all data associated with direct messages, and is parsed out from & into the following:

![]()

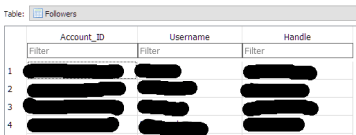
Followers & Following
Contains data from followers.js & following.js which has account IDs for all users that follow the user in question. This data can be used by investigators to see who the suspect was potentially able to be in contact with.



Imported Contacts
Contains data from contacts.js which are all contacts that a user chooses to import from their personal contact application, into Twitter. Unfortunately, I could not find a way to correlate the Contact_ID/Phone Number with a Twitter Account_ID, as the Contact_ID number is not present in any other file in the archive, and Twitter’s API does not allow access to Contact_IDs or phone numbers. This data can be good material to corroborate an analysis done on a suspect’s phone to implicate the suspect did have this number in their contacts. Data is parsed into the following:

![]()

Logins_From_IP
This contains data from ip-audit.js and is parsed into account ID, username, and handle of the suspect user, and more importantly, the IP address used to login for that specific Twitter session, and the date at which it occurred This is very interesting information, as with the public IP address of each session, it is possible to determine general location data with the IP address as well.

![]()

Tweets
This contains data from tweet.js and is parsed into the following:

![]()

Conclusion
Many more artifacts reside in this archive, however, I just wanted a working script that can be able to obtain more artifacts than Axiom’s pull. More features are planned to be released with more optimizations. More info about the twitter-archive-parser can be found on my GitHub Repo.